Em artigo recente para a Tecnologística, escrevi brevemente sobre o status de utilização de IA e Machine Learning em planejamento da demanda, ilustrando os diferentes usos com exemplos de empresas destacadas. Recebi, como devolutiva, alguns questionamentos sobre como iniciar uma jornada de analytics em previsão de vendas, que ainda parece algo muito distante da realidade das empresas e, por vezes, algo sofisticado e complexo.
Por isso, eu e a Jessica Silva, que divide comigo o curso de previsão de vendas do ILOS, decidimos fazer alguns posts para tentar desmistificar e trazer algumas orientações práticas sobre o uso de ferramentas e bibliotecas disponíveis em linguagens open-source, como o Python e o R. A previsão de vendas é uma tarefa que normalmente envolve análise estatística, aprendizado de máquina ou aprendizado profundo, dependendo da complexidade do conjunto de dados e do objetivo deste processo preditivo.
Vamos começar esta série de publicações com um exemplo muito simples de aplicação de modelos de previsão de vendas em Python, que possui uma variedade de bibliotecas para lidar com esse tipo de tarefa. Algumas das bibliotecas Python mais úteis para a previsão de vendas incluem:
- Pandas: manipulação e análise de dados;
- NumPy: operações matemáticas;
- Matplotlib e Seaborn: visualização de dados;
- Sklearn: aprendizado de máquina;
- Pmdarima: função de auto arima;
- Statsmodels: modelos estatísticos, incluindo regressão linear e testes estatísticos;
- Prophet: previsões de séries temporais (desenvolvido pelo Facebook);
- Keras e TensorFlow: modelos de aprendizado profundo.
Neste primeiro texto, nosso objetivo é mostrar o uso de um modelo mais sofisticado do que a maioria das empresas utilizam e, para isso, escolhemos um modelo SARIMAX, uma variação do modelo ARIMA que permite lidar com séries temporais com tendência de crescimento, sazonalidade marcada e a consideração de variáveis exógenas, como descontos, feriados, preço da concorrência ou investimentos comerciais diversos.
Para tornar mais simples essa primeira incursão, vamos utilizar a função auto_arima da biblioteca pmdarima, que é equivalente a um modelo SARIMAX da biblioteca statsmodels. A diferença é que a função auto_arima tenta encontrar automaticamente os melhores parâmetros do modelo (os termos AR, I, MA, sazonal e a ordem deles) usando critérios como o critério de informação de Akaike (AIC) ou o critério de informação bayesiano (BIC). Isso pode ser muito útil quando você não tem uma boa ideia de quais parâmetros usar.
Para este caso, vamos utilizar o ambiente de desenvolvimento Spyder, porém existem vários desktops de python disponíveis online, incluindo tutorias de instalação e primeiros passos.
Passo 1: Importar as bibliotecas necessárias

Na primeira etapa, são importadas as bibliotecas que serão utilizadas. Elas são os “pacotes” que contêm as funções que precisamos usar para fazer a modelagem e a previsão.
Passo 2: Carregar seus dados
A base de dados já tratada contém três colunas: uma de data, uma com as vendas e outra com a variável exógena selecionada (trataremos o processo de seleção de variáveis em outro post).

Passo 3: Dividir seus dados em treinamento e teste

Fazer essa divisão permite que mitiguemos a chance de ocorrer o overfitting do modelo. No caso, optamos por direcionar o grupo de teste e o grupo de treino, colocando para simplificação o último ano de observação como o grupo de teste.
Passo 4: Definir e ajustar o modelo

Aqui efetivamente é aplicado o modelo SARIMAX. Vale observar que não foi necessária a definição de nenhum dos parâmetros do modelo, a função tem embutida um algoritmo de otimização que seleciona o modelo mais adequado, ou em outras palavras, aquele que minimiza o erro.
Passo 5: Fazer as previsões

Nesta etapa é informada a quantidade de observações no futuro que se deseja prever, que neste caso foi de 12 meses. O ARIMA, e seus derivados, permite realizar previsões para múltiplos períodos. Também é importante dar entrada nos dados previstos para a variável exógena para este mesmo horizonte de tempo.
Passo 6: Crie um dataframe com as previsões

Um dataframe foi criado para facilitar a geração dos gráficos, que é o próximo passo.
Passo 7: Plotar em gráfico os dados originais e as previsões

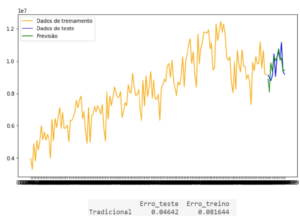
Aqui calculamos o indicador MAPE (Mean Absolute Percentage Error). Em ambos os cenários, nota-se uma boa aderência do modelo a série. Fazer essa análise do erro em ambas as amostras ajuda a enxergar potencial cenário de overfitting. Caso o erro no treino fosse muito baixo e o erro no teste fosse muito alto, isso nos sinalizaria um caso de “modelo viciado nos dados”, ou seja, o modelo é capaz de prever de forma quase que perfeita a série dentro da amostra de treino, porém tem pouca utilidade fora daquela amostra.
Existem outras métricas de erro de previsão, como AIC, MPE, RMSE, entre outros que devem ser analisados quando avaliar um modelo. Além disso, é sempre uma boa prática verificar os resíduos do modelo para garantir que não haja padrões remanescentes não capturados pelo modelo.
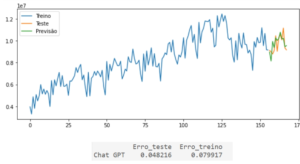
Este é um exemplo simplificado, mostrando que com poucas linhas de código é possível utilizar um modelo bastante sofisticado, usando inclusive uma variável exógena, o que não é muito comum nas empresas. Não sabe criar o código? Uma dica: o ChatGPT sabe. Você só precisa pedir e entender como parametrizar corretamente o modelo para poder criticá-lo. Em anexo nós rodamos o código sugerido por ele com alguns pequenos ajustes de parametrização de amostra de teste e treino. Os resultados podem ser vistos lá.
Claro que antes de sair usando o modelo, seria útil fazer uma análise exploratória de dados, que pode incluir a verificação de estacionariedade, a detecção de outliers, a transformação dos dados (se necessário, por exemplo, se a série não for estacionária) e a visualização dos dados para entender quaisquer tendências ou padrões subjacentes.
Nos próximos posts, pretendemos dar exemplos de como tratar e limpar o baseline de vendas de forma automatizada, como utilizar técnicas de ensemble ou combinação de métodos para melhora da acuracidade, exemplo prático de redes neurais profundas em séries temporais com modelos LSTM com ajuste de hiperparâmetros e mais. Tudo para tentar ajudar a tornar tangível e mostrar que com um pouco de esforço, pesquisa e estudo, dá para avançar em Analytics para previsão de vendas!
ANEXO – CHAT GPT
Resultados:

Leonardo Julianelli
https://ilos.com.brSócio Executivo do ILOS. Graduado em Engenharia de Produção pela EE/UFRJ, é Mestre em Administração de Empresas pelo COPPEAD/UFRJ com extensão na EM Lyon, França, e doutor em Engenharia de Produção na COPPE/UFRJ. Tem diversos artigos publicados em periódicos e em revistas especializadas, sendo um dos autores do livro: “Previsão de Vendas: Processos Organizacionais & Métodos Qualitativos e Quantitativos”. Suas áreas de pesquisa são: Planejamento da Demanda, Serviço ao Cliente no Processo Logístico e Planejamento de Operações. Atuou durante 8 anos no CEL-COPPEAD/UFRJ, ajudando a organizar a área de Ensino em Logística. Em consultoria, realizou diversos projetos na área de logística, como Diagnóstico e Plano Diretor, Previsão de Vendas, Gestão de Estoques, Planejamento da Demanda e Plano de Capacitação em empresas como Abbott, Braskem, Nitriflex, Petrobras, Promon IP, Vale, Natura, Jequití, entre outras. Como professor, ministrou aulas em empresas como Coca-Cola, Souza Cruz, ThyssenKrupp, Votorantim, Carrefour, Petrobras, Vale, Via Varejo, Furukawa, Monsanto, Natura, Ambev, BR Distribuidora, ABM, International Paper, Pepsico, Boehringer, Metrô Rio, Novelis, Sony, GVT, SBF, Silimed, Bettanin, Caramuru, CSN, Libra, Schlumberger, Schneider, FCA, Boticário, Usiminas, Bayer, ESG, Kimberly Clark e Transpetro, entre outras.